Benchmarking open data automatically
(with Tom Heath and Jamie Fawcett), ODI Report ODI-TR-2015-000
This paper is part of a series produced by the Open Data Institute, as part of the Partnership for Open Data (POD), funded by the World Bank.
Executive summary
As open data becomes more widespread and useful, so does the need for effective ways to analyse it.
Benchmarking open data means evaluating and ranking countries, organisations and projects, based on how well they use open data in different ways. The process can improve accountability and emphasise best practices among open data projects. It also allows us to understand and communicate how best to use open data for solving problems. Future research and benchmarking exercises will need to happen on a larger scale, at higher frequency and less cost to match the rising demands for evidence.
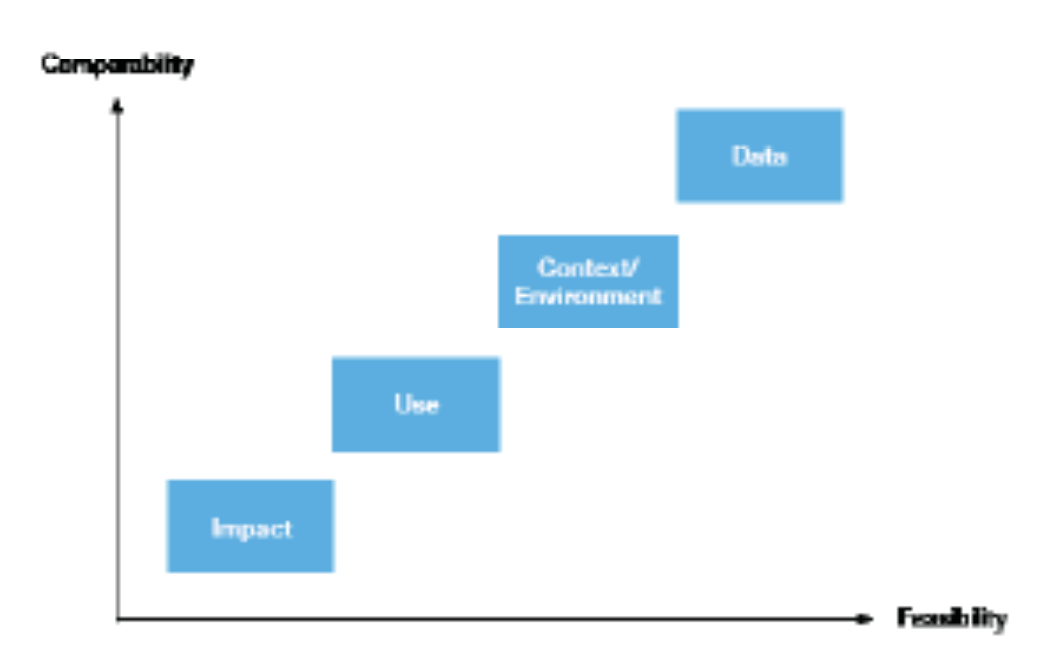
This paper explores individual dimensions of open data research, and assesses how feasible it would be to conduct automated assessments of them. The four dimensions examined are: open data’s context/environment, data, use, and impact. They are taken from the Common Assessment Methods for Open Data (CAF), a standardised methodology for rigorous open data analysis. The paper proposes a comprehensive set of ideal constructs and metrics that could be measured for benchmarking open data: from the existence of laws and licensing as a measure of context, to access to education as a measure of impact.
Recognising that not all of these suggestions are feasible, the paper goes on to make practical recommendations for researchers, developers and policy-makers about how to put automated assessment of open data into practice:
- Introduce automated assessments of open data quality, e.g. on timeliness, where data and metadata are available.
- Integrate the automated use of global performance indicators, e.g. internet freedoms, to understand open data’s context and environment.
- When planning open data projects, consider how their design may allow for automated assessments from the outset.
Improving automatic assessment methods for open data may increase its quality and reach, and therefore help to enhance its social, environmental and economic value around the world. For example, putting an emphasis on metadata may ensure that data publishers spend enough time on preparing the data before their release. This paper will help organisations apply benchmarking methods at larger scale, with lower cost and higher frequency.